
Before starting with RAFT let me grab the definition of consensus from Wikipedia.
A process of decision-making that seeks widespread agreement among group members.
Well, that gives more clarity 😀.
In short, if everyone in a group agrees on a single thing then they have a consensus.
Consider that i have an application service comprising of a primary node and a few secondary nodes. To serve the purpose of availability if something happens to the primary node one of the secondary nodes should take the charge.
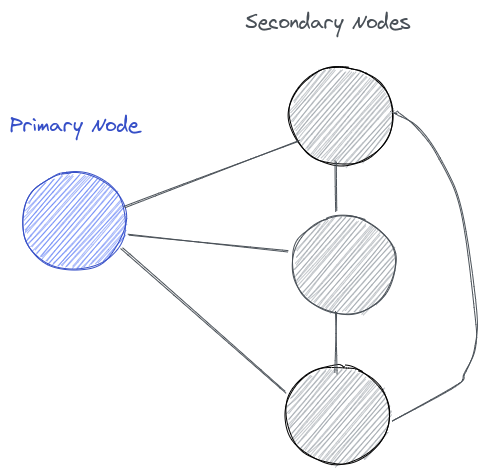
We could use a floating IP address and some watchdog scripts for the system to achieve availability.
But what happens when there is data involved 😰.
well, we need to synchronize data across these nodes, the easy way to implement this is to replicate the data across all nodes.
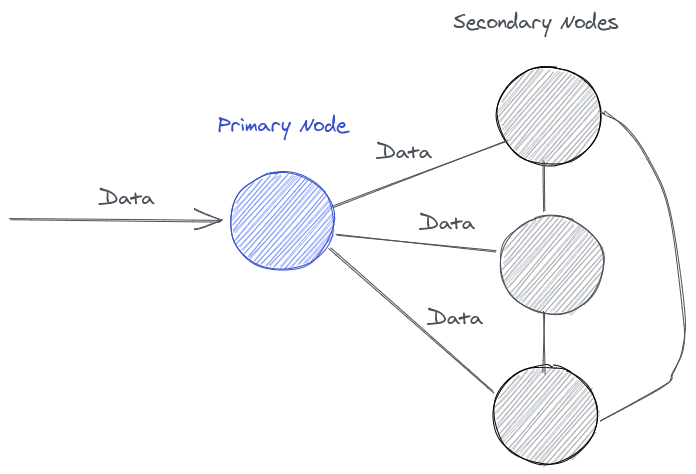
what happens when the network goes down?
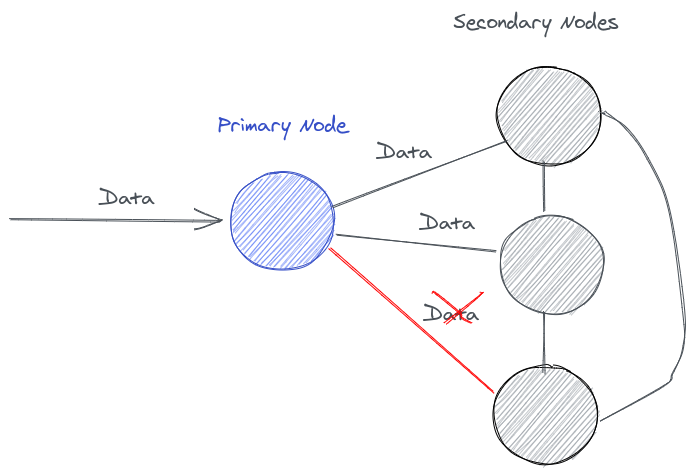
Now we have lost some data, what happens when the primary node fails , who will we choose as the next primary node 😭.
How would we approach this problem?
The real question is how do i achieve consensus on a system where there could always be a chance of failure (== Distributed System 😊)?

Don’t worry a raft is here to the rescue, It’s not something that you have hoped for 😝.
Well, let me redefine what kind of RAFT we are using here.
RAFT is a consensus algorithm (which is similar to PAXOS but with simplicity in mind) that is designed to achieve fault tolerance in a distributed system.
So how does raft work 🤷♂️?
It’s easy to comprehend there are three roles for a node in a raft based system. (Let me explain this in terms of GOT 🐲⚔)
1) The leader

2) The Follower

3) The Candidate

Initially, every node in the system becomes a follower
If the nodes don’t receive any kind of messages for a short while, a random timer is set off on the nodes (100–150 ms), At some point a node reaches the timers end and becomes a candidate. It creates a new term *(eg: 2010–2014, something hex in nature is more appropriate)*and votes for itself and proposes for an election to the other nodes.
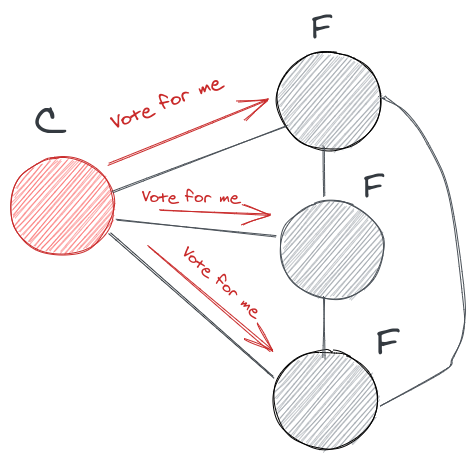
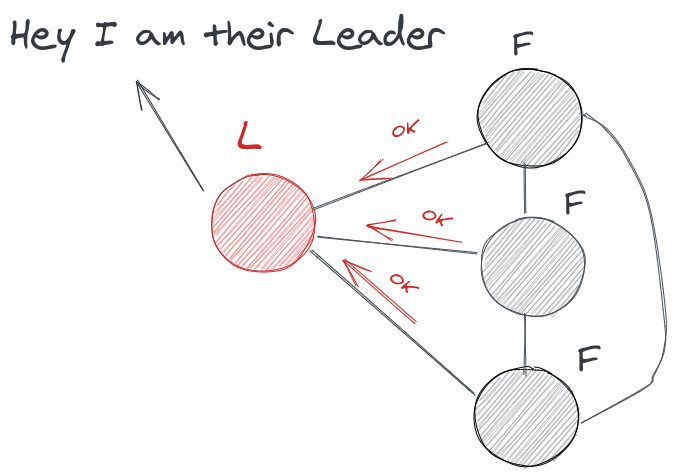
The voting message consists of an event log from the candidate to check whether it has the up-to-date information of the system and the followers cross-checks that with their own local-event log if it has a credible information then all the nodes votes for that candidate. The candidate then checks for the majority and becomes a leader.
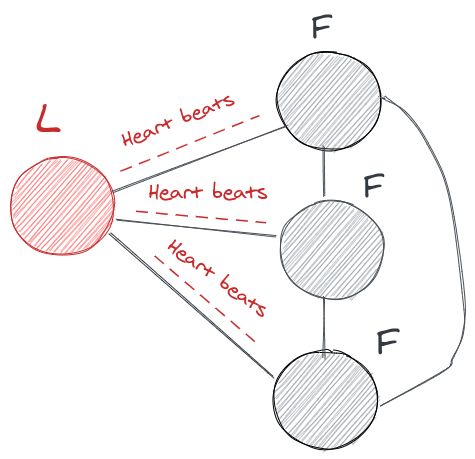
The Leader now has to send heartbeat messages at specific intervals to all its followers to denote that it’s still alive.
So the obvious question would be what happens if the leader gets disconnected, or by some mishap, it went offline. All the nodes would go into a state where they randomly set a timer and restarts the election process for a new term.
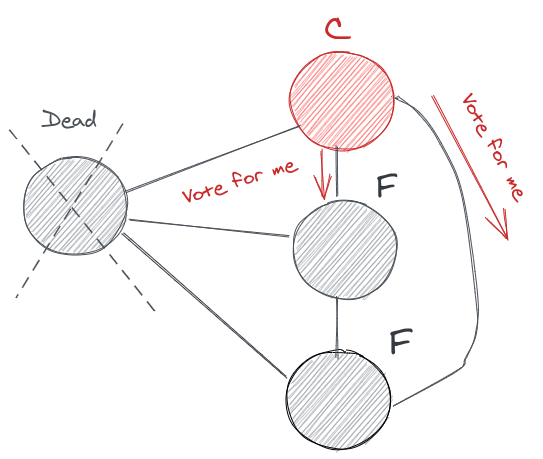
And the process continues again. When the failed node comes online it will see there was a new term and a new leader was elected by the system, it steps down from its position and follows the new leader.
This was easy to solve right?
Wait, there is another possibility of split voting what happens when there are two candidates who spawns at the same time (Random timers ain’t that random 😝).
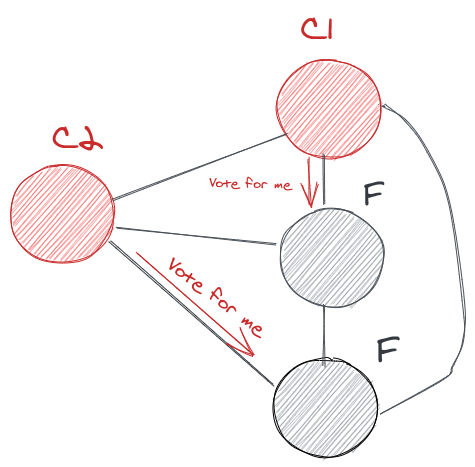
Don’t worry , there are some constraints here, a follower could only vote for a term once if it votes for c2 then it cant what for c1 (From the above figure), the candidate c1 and c2 cant vote for each other since they voted themselves for the term.
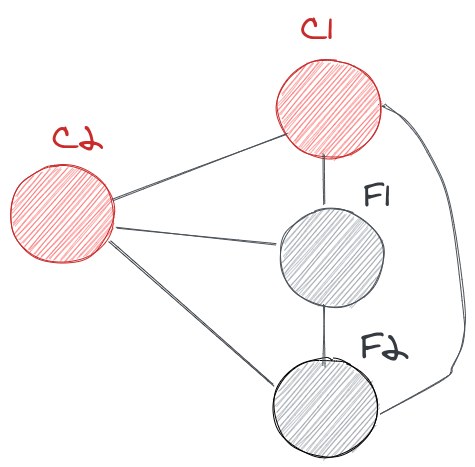
Since no one had a majority, both the candidates are given a random timer to start an election for a new term (term 2).
Here in the figure below c2 times-out first and requests for an election for the new term and everyone including c1 accepts that and vote for c2.
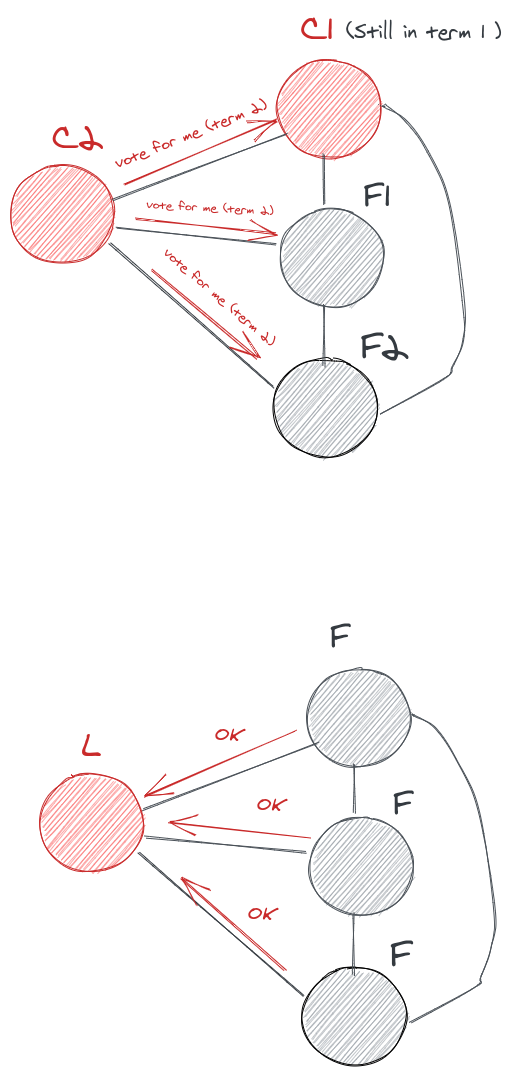
And now c2 becomes the leader for the term 2 election.
So that’s all for this part, I hope you guys got an idea of how leader election works in RAFT, on the next part we will discuss more on log replication and data synchronization between nodes.